Featured Projects

New York Taxi Trip Duration: Regression
- Python, Pandas, scikit-learn(for comparison)
- Machine Learning algorithms: Decision Tree, Elastic Net
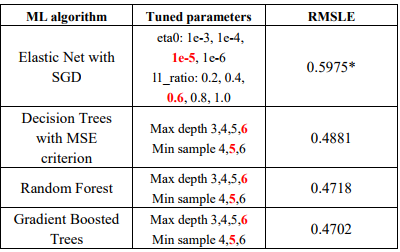
- Evaluation Metrics:Root Mean Squared Logarithmic Error(RMSLE)
In this project, the dataset that we choose was orig-inally published by the NYC Taxi and Limousine Commis-sion (TLC). The data was sampled and cleaned for the pur-poses of Kaggle playground competition. Based on individ-ual trip attributes, we should predict the duration of each trip in the test set. In this context, we hypothesized that by our machine learning algorithms could be as predictive as the ones in scikit-learn and that we will be able to predict the trip duration with a Root Mean Squared Logarithmic Error (RMSLE) lower than 50% of the competitors.
Check it out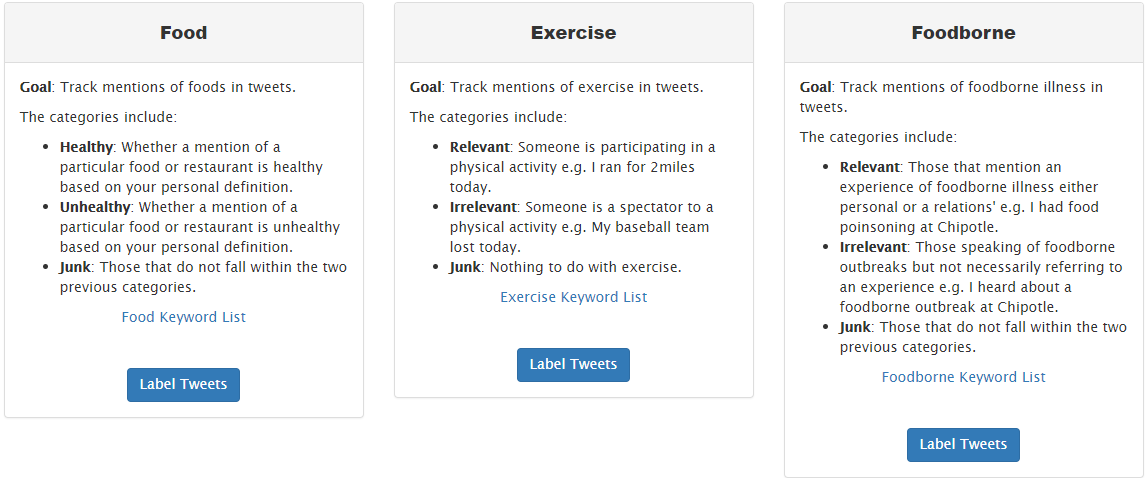
Twitter: Food contextual tweets sentiment analysis
- Python, Pandas, Scikit-Learn, NLTK, Tensor Flow, keras
- Algorithms: Random Forest, Support Vector Machine, Word embeddings(Word2Vec: CBOW, Skip-Gram, Glove, Doc2Vec) + CNN
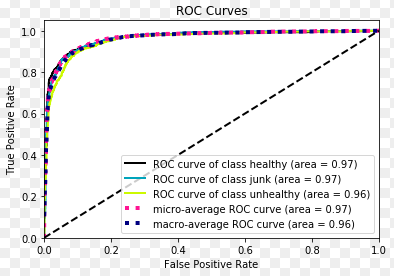
- Evaluation Metrics:Accuracy (Deep Neural nets), ROC, AUC values (SVM, Random Forest)
the data is collected in the form of json format, that collected data is loaded into dataframes. Apart from the existed columns, I added a new column to the existed dataframe with the tweet content of that corresponding row. Removed the special charactes and mentioned urls (since the url is in random format) with help of regular expression patterns, and transformed the tweet text into alpha numeric sentences. After text formatting, filetered the dataframes into 3 different dataframes (food, borne and exercises) based on their context column attribute of the data. After data cleaning, the I built and trained the classifiers on data to classify the given tweets into borne, food and exercise contextual target classes.
Check it out
Animal Shelter Outcomes: Classification
- R, GlmNet, gbm, caret
- Machine Learning algorithms: Decision Trees, Random Forests, Gradient Boosting, NeuralNets
- Evaluation Metrics:Log loss, AUC value
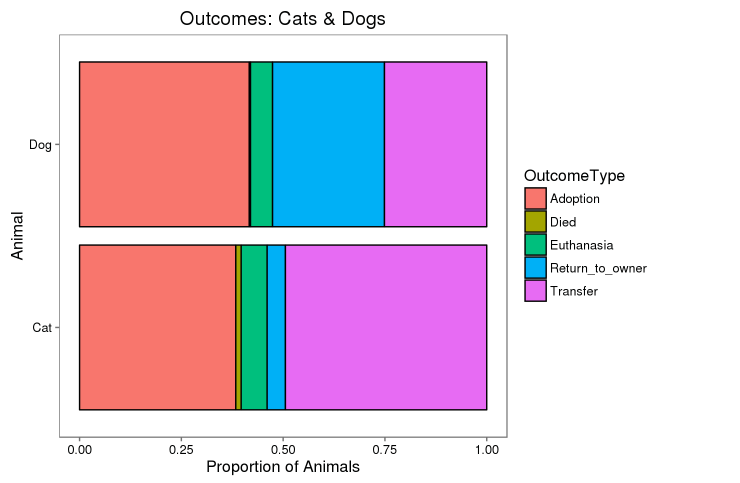
Using a dataset of intake information including breed, color, sex, and age from the Austin Animal Center, we should predict the outcome for each animal. The objective of this project is to predict the outcome of animals placed in shelters given features such as the animal’s age, breed, and color. There are 5 possible outcomes for each animal (shown in figure #) with euthanasia being the worst outcome. From the predictions, the shelter hopes to be able to determine which animals are likely to be euthanized as well as find trends into what features increases the chance for adoption. This provides a chance for shelters to make an effort to aid animals with a low chance of adoption. The overall goal is to decrease the yearly number of animals euthanized. This project has 3 phases, they are preprocessing, feature engineering and building the models, finally evaluation of models. I built Multinomial regression, Support Vector Machines, Random Forest, Neural Network and XGboost classifiers on the data, after fine tuning with grid-based approach, the Random Forest model performed quite well with AUC of 0.82 and OOB error was about 35% for this model.
Check it out
Playing Doom with Reinforcement Learning and Linear Feature Repre-sentations
- Python, OpenCV, Reinforcement Learning: SARSA, Q-Learning
- Evaluation Metrics: Average reward on episode
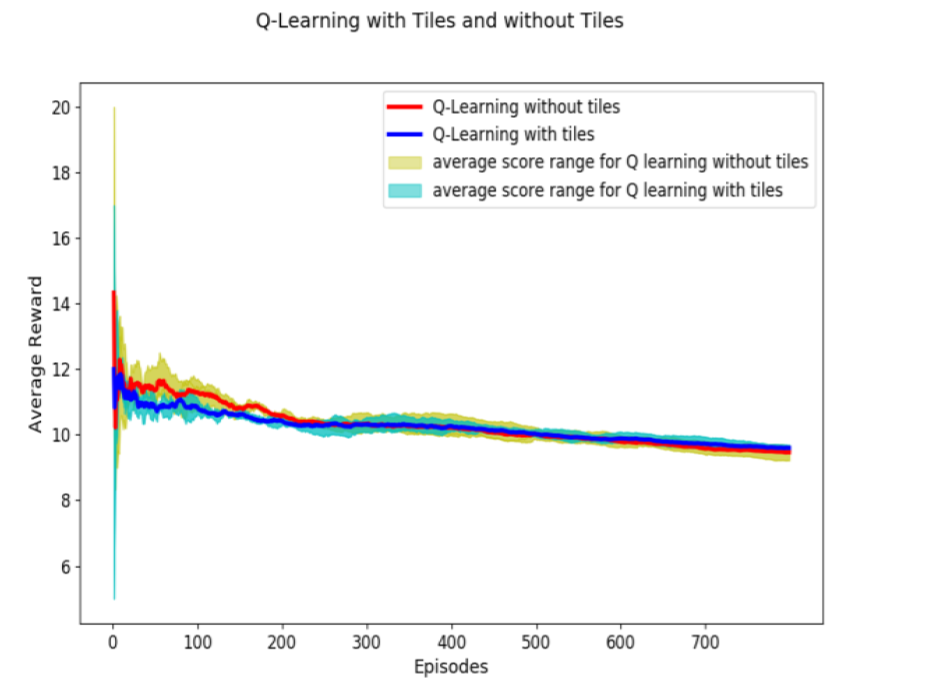
In this Project, our agent is in a closed room and has to battle against several demons that can be classified in two types: demons throwing fire balls (they only move to the sides), and short-distance attack demons that slowly approach to our agent. Both of them respawn. The specific characteristics of the game are as follow. The objective on each episode is to kill as many monsters. For every monster killed, 1 point is received, and for every time our agent is killed, one point is subtracted. There are three possible actions for our agent: turn left, turn right and shoot. To complete the goal proposed in the simulator, the agent needs to reach 15 as the best 100-episode average reward. To get 15 points in one episode our agent either has to kill 16 monsters before being killed, or kill 15 monsters without being killed. In this work, we create a machine learning agent that play Doom Defend Line, which is a scenario from the classic game Doom. We hypothesize that by using two different RL methods separately we can create an agent that is competi-tive enough to score 15 points in average through 100 con-secutive episodes which is the goal proposed in the simula-tor website.
Check it out